Exploring V-Net: A Revolutionary Approach to 3D Image Segmentation
Written on
Chapter 1: Introduction to V-Net
Welcome to an enlightening exploration of V-Net, a powerful counterpart to the well-known U-Net, specifically designed for 3D image segmentation. This guide will provide a comprehensive understanding of V-Net, its architecture, and its contributions to deep learning in medical imaging.
As we embark on this journey, you may already recognize U-Net as a revolutionary architecture that has transformed image segmentation in computer vision. Today, we will focus on its larger sibling, V-Net.
The foundational paper, "VNet: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation," authored by Fausto Milletari, Nassir Navab, and Seyed-Ahmad Ahmadi, introduced a groundbreaking approach for analyzing 3D images. This article will delve into the unique features and architectural innovations of V-Net, making it accessible for seasoned data scientists, aspiring AI enthusiasts, or anyone intrigued by the latest technological advancements.
A Quick Recap of U-Net
Before we dive into the intricacies of V-Net, let’s briefly revisit U-Net, the architectural inspiration behind it. If you're new to U-Net, don’t worry! I’ll provide a straightforward tutorial on its architecture, allowing you to grasp the concept in just five minutes.
Here's a condensed overview of U-Net:
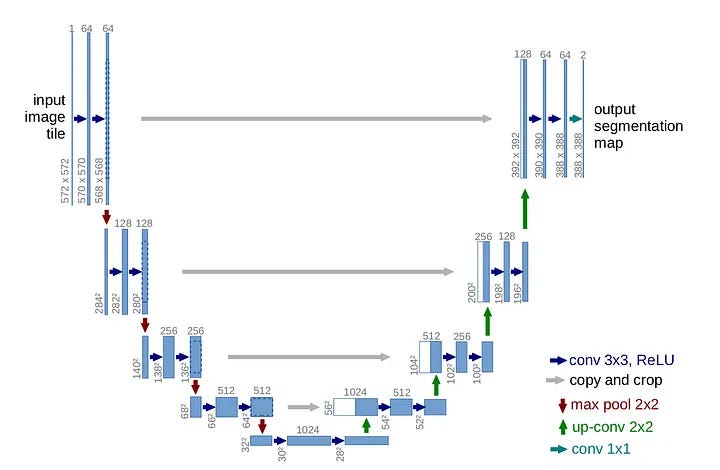
U-Net is renowned for its symmetrical 'U' shape, consisting of two distinct paths:
- Contracting Pathway (Left): This pathway gradually reduces the image resolution while increasing the number of filters.
- Expanding Pathway (Right): Mirroring the contracting path, this section decreases the number of filters while enhancing the resolution until it matches the original image size.
The brilliance of U-Net lies in its innovative use of 'residual connections' or 'skip connections.' These connections link corresponding layers in both pathways, enabling the network to preserve high-resolution details often lost during downsampling.
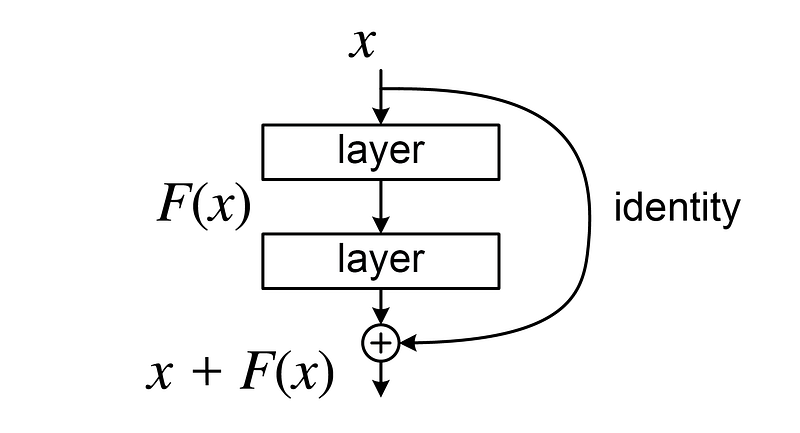
This design is crucial as it facilitates better gradient flow during backpropagation, particularly in the early layers. By addressing the vanishing gradient problem—where gradients diminish to zero and impede learning—U-Net enhances the training process:
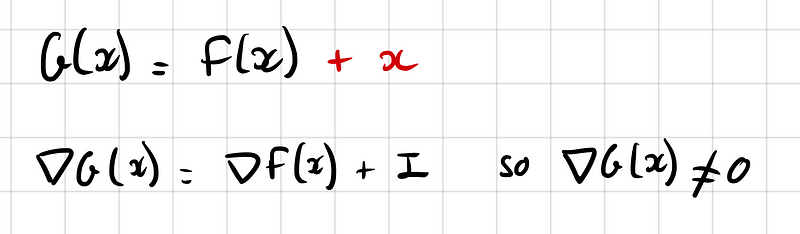
With this foundational understanding of U-Net, let’s transition to the innovative features of V-Net.
Chapter 2: Distinctive Features of V-Net
What Differentiates V-Net from U-Net?
Let's explore the key differences:
#### Difference 1: Transition to 3D Convolutions
The most evident distinction is that V-Net is designed for 3D image segmentation, utilizing volumetric data (such as MRI and CT scans). Thus, it employs 3D convolutions in place of 2D convolutions, addressing the complexities of medical imaging.
#### Difference 2: Activation Functions – PreLU over ReLU
While ReLU has become a popular choice in deep learning due to its computational efficiency, it can suffer from the 'Dying ReLU problem.' To counter this, V-Net adopts Parametric ReLU (PReLU), allowing the network to learn the slope instead of hardcoding it, thereby minimizing inductive bias.
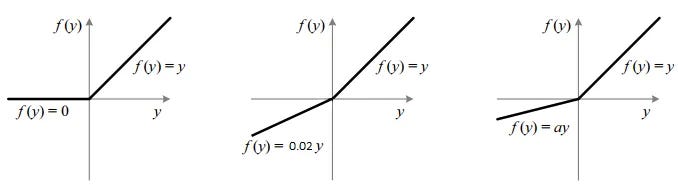
#### Difference 3: Loss Function Based on the Dice Score
V-Net's most significant contribution lies in its use of the Dice loss function instead of the conventional cross-entropy loss. The Dice score is particularly effective in situations where class imbalance is prevalent, as is often the case with medical images.
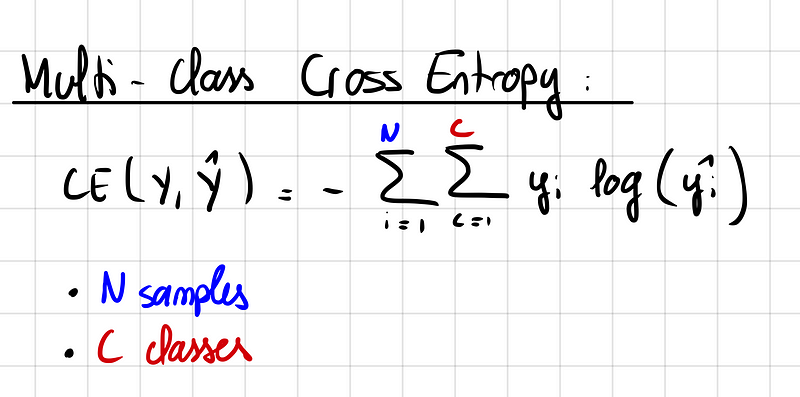
This approach measures the overlap between predicted regions and ground truth, addressing the challenges posed by backgrounds dominating the dataset.
Consequently, V-Net presents a more reliable measure of performance even in imbalanced scenarios.
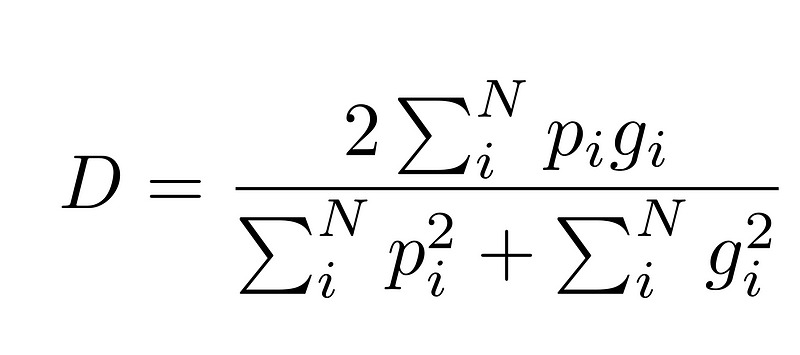
In practice, combining the strengths of both Cross Entropy Loss and Dice Loss often yields optimal results.
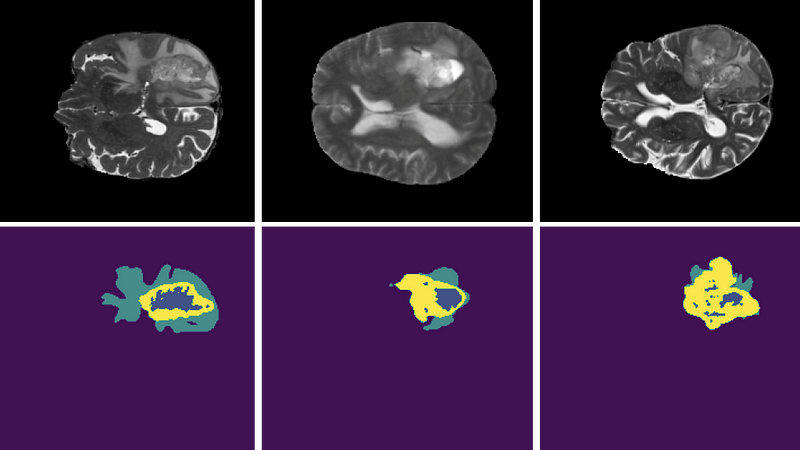
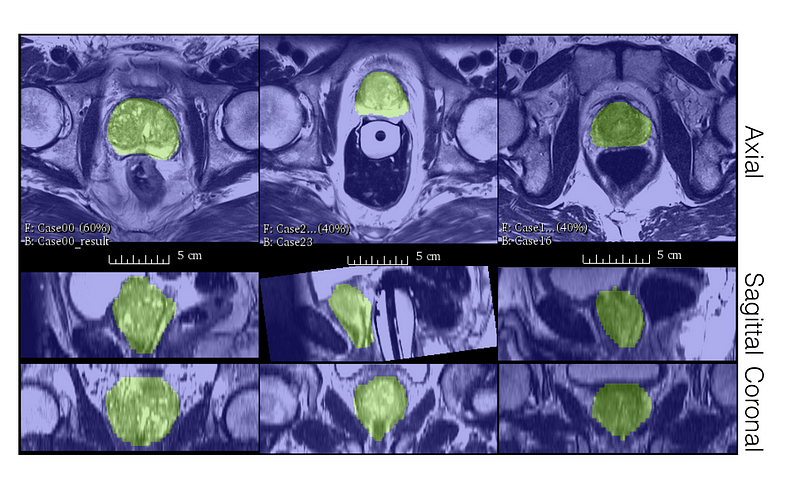
V-Net's Performance Assessment
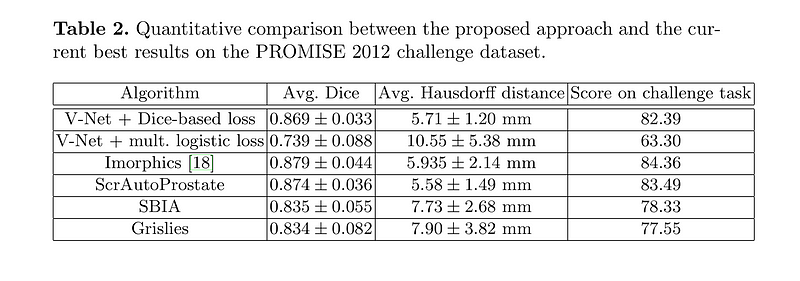
Now that we've examined V-Net's unique aspects, you might be wondering about its real-world efficacy. The authors tested V-Net on the PROMISE12 dataset, which was established for the MICCAI 2012 prostate segmentation challenge. Despite training on just 50 Magnetic Resonance (MR) images, V-Net demonstrated impressive qualitative segmentations and achieved commendable Dice scores.
Main Limitations of V-Net
Despite its achievements, V-Net is not without limitations. Here are some areas for improvement:
- Model Size: The shift from 2D to 3D significantly increases memory requirements, limiting batch sizes and complicating GPU memory management.
- Lack of Unsupervised Learning: V-Net relies solely on supervised learning, overlooking the potential advantages of unsupervised techniques, especially given the abundance of unlabeled scans.
- Uncertainty Estimation: V-Net does not incorporate uncertainty estimation, limiting its ability to assess prediction confidence—a critical area for enhancement through Bayesian Deep Learning methods.
- Robustness Issues: Like other convolutional neural networks (CNNs), V-Net can struggle with generalization, particularly when faced with variations in data quality or distribution.
Conclusion
V-Net has made significant strides in the field of image segmentation, particularly within medical imaging. Its transition to 3D convolutional networks and the introduction of the Dice Coefficient have set new benchmarks. Despite some limitations, V-Net remains an essential model for anyone tackling 3D image segmentation tasks. Future enhancements could explore unsupervised learning and the integration of attention mechanisms.
Thank you for reading! For more AI tutorials, feel free to check my GitHub compilation.
If you found this article valuable, consider subscribing to stay updated on my latest insights!