Harnessing Generative AI for Zoning Analysis and Capacity Computation
Written on
In this series of articles, we explore experiments utilizing Generative AI, specifically large language models (LLMs), to simulate household location preferences and urban development trends, while interpreting zoning regulations to automatically generate algorithms for computing capacity in Oakland, CA, USA, and Auckland, NZ.
Creating algorithms that incorporate zoning constraints has consistently posed significant challenges, similar to those encountered in software systems tasked with processing and interpreting natural language. For years, computer scientists have endeavored to devise solutions to navigate these difficulties, motivated by the vast potential of systematically structuring knowledge found in human-readable texts, including legal frameworks and regulations.
The 1980s witnessed a surge in interest surrounding logical programming, particularly marked by the introduction of the PROLOG language. This period was rife with promises of transforming knowledge representation and reasoning, yet those ambitions were not fully realized. However, recent advancements in neural network architectures and their exceptional capabilities in natural language processing, as demonstrated by large language models, have rekindled interest in addressing these long-standing issues.

Zoning regulations and their constraints are widely applicable across various sectors, with a key function being the assessment of construction capacity allowed on specific parcels of land. This assessment is crucial for both urban planning and the real estate industry. However, a critical distinction between these two fields is the scale of analysis. Urban planning typically covers large geographic areas, while real estate often concentrates on smaller parcels. As the number of parcels increases, the necessity for robust and efficient methods for automated capacity computation becomes even more apparent, especially in land use simulations, where the scale of analysis can require evaluations of thousands or tens of thousands of individual parcels.
Zoning data presents unique challenges due to its lack of structured representation. Across different urban environments, not only do the specific values for constraints, such as setbacks and height limitations, vary, but the attributes defining capacity calculations can also differ. Furthermore, some constraints defy simple quantification, necessitating complex methodologies to gather additional data for accurate capacity assessments. For instance, height restrictions may depend on the average height of buildings within a block, or geometric limitations might consider the spatial relationships with adjacent structures. The computation of development capacities involves more than just gathering input parameters like setback lengths; it requires defining the sequence of steps necessary to reach the final computation. This computational process can vary significantly across different land use types, such as residential and commercial zones.
From a software engineering standpoint, both data processing and capacity calculation methods appear straightforward. However, the interpretation of natural language remains one of the most challenging aspects. Our previous efforts focused on creating domain-specific languages (DSLs) that urban planning professionals could learn. This involved interpreting zoning laws and codifying them so that a custom DSL parser could convert them into computable algorithms. While this approach proved innovative and significantly improved upon earlier methods, it posed considerable challenges. Developing these DSLs is inherently complex, and requires professionals without software development backgrounds to learn how to translate constraints into the DSL. Ultimately, while we found a way to accurately represent intricate constraints and enable automatic capacity computation, this approach still necessitated substantial human intervention.
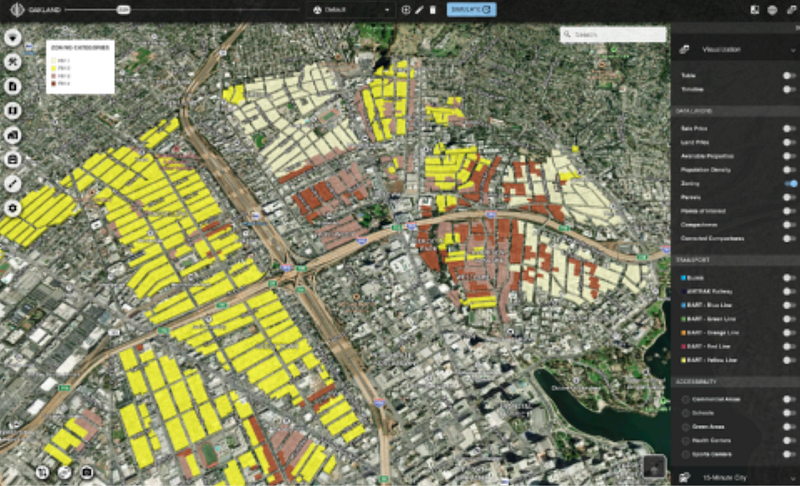
Large language models and other generative AI systems have demonstrated remarkable proficiency in natural language comprehension and source code generation. With these capabilities in mind, we embarked on an intriguing experiment—inputting zoning documents into these models to evaluate the level of automation achievable. This trial was conducted across various regions, including Oakland, USA, and Auckland, New Zealand, with the aim of assessing the models' capacity to interpret and generate algorithms that encapsulate the intricate rules and regulations found in zoning documentation.
OAKLAND, USA
We initiated the process by extracting pertinent sections of the local zoning code, focusing on specific residential and mixed-use categories (RM and C), as the LLM we employed lacked detailed knowledge in this domain. After feeding the model the relevant information, we began querying it about density, asking questions such as:

The model successfully interpreted tables and summarized data on particular zoning categories, which was promising, although it remained distant from a format that could be directly processed by an algorithm. We then advanced the inquiry, asking the model to detail RM-3 maximum lot coverage not in natural language but as a JSON data object:
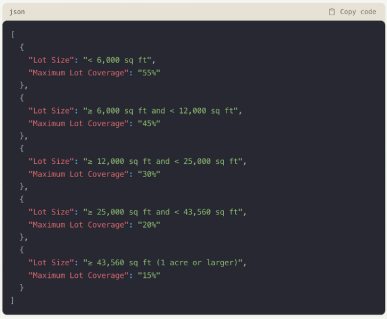
Clearly, this output could serve as input for an algorithm, allowing interpretation of the conditions in the “Lot Size” field to create a function. But could the LLM generate that function autonomously? It turns out, it could.
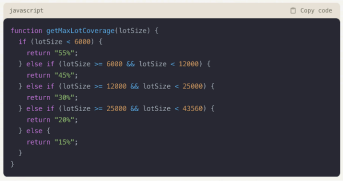
In summary, this generative AI successfully produced a function that, given the area of a lot, returns the maximum allowable coverage in JavaScript. We also explored setbacks (in relation to parcel area) and obtained the following function:
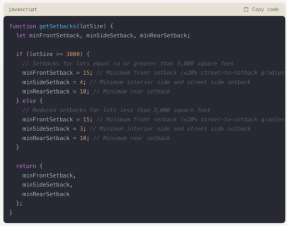
Lastly, we challenged the model to provide code for determining the maximum allowed height based on slope (a parameter included in this zoning code) across all four residential/mixed-use categories, rather than just one as in previous examples.
AUCKLAND, NEW ZEALAND
After inputting local zoning documents, we tasked the LLM with creating a function to verify whether a specified building polygon complies with building coverage constraints. This task was further complicated by the necessity of computing polygon areas, yet the resulting algorithm was accurate:
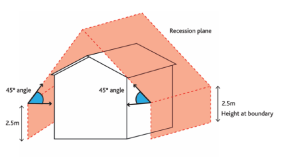
We chose this urban area for our experiments due to its inclusion of recession planes, presenting a unique challenge in extracting zoning information and creating algorithms for capacity calculations. Despite testing various prompts, we struggled to generate a correct function for assessing any properties of these structures.

After facing this challenge, we prompted the LLM to devise a generic algorithm for capacity calculation, adhering to area constraints.
It became evident that the model's output was incomplete and failed to account for significant restrictions present in the area. While improved results might be achievable through carefully staged prompts, it is clear that the model lacks a comprehensive grasp of the rules.
CONCLUSIONS
It is crucial to recognize that these experiments required substantial manual involvement, including the identification and retrieval of relevant documents, as well as an iterative process of prompt engineering. Recent initiatives have aimed to automate this process, offering functionalities for automated web scraping and prompt creation. During our experiments, we tested AgentGPT but found the results unsatisfactory—the technology shows promise but is not yet sufficiently mature for this type of data.
A significant limitation of existing large language models (LLMs) is their inability to interpret and analyze maps and spatial data formats. Beyond processing textual descriptions of zoning categories and overlays, a vital aspect of zoning acquisition involves determining the specific zoning designation and applicable overlays for each parcel. This determination typically relies on visual inspection of maps featuring multiple vector layers, often provided in formats like shapefiles or other geospatial data representations. In cases where parcel categorization is relatively simple, and the necessary layers are available digitally, this limitation may not severely hinder the performance of large-scale capacity calculation algorithms. However, the lack of effective reasoning over and integration of spatial data representations presents a significant bottleneck, necessitating human expertise and intervention for accurate and comprehensive zoning analyses.
The outcomes of these experiments indicate that cutting-edge large language models (LLMs) have the potential to significantly enhance zoning acquisition processes, particularly for large-scale projects requiring capacity calculations across numerous parcels. However, human involvement remains crucial during certain workflow stages, and notable limitations were encountered when addressing complex geometric rules. Nevertheless, the rapid advancements in this field suggest that innovative refinements may emerge in the near future—potentially within months—that could allow us to overcome current limitations.
By Federico J. Fernandez, Founder & CEO of Urbanly.
For further insights, refer to our report on Generative AI for Urban Governance.